Generating Pusheen with AI
27 April 2018You're reading the non-expert version of this post I wrote for people that don't have a technical background. If you would like to read the more technically in-depth version, click the expert button above.
You're reading the expert version of this post I wrote for people that do have a technical background. If you would like to read the less technically in-depth version, click the non-expert button above.
I made a machine learning program that generates new (sometimes novel!) Pusheen pictures!
(I don't claim any ownership of Pusheen or anything Pusheen related, which is trademarked by Pusheen Corp.) It's no secret that my girlfriend and I both are huge fans of Pusheen the cat, which many people know from the cute Facebook sticker sets. So, for her birthday I set out to try to create a machine learning program to create cat pictures for her to enjoy! To set some expectations for this post, I only did this for a fun project and didn’t really know what I expected to get out of it given that in all the data available there are really only a handful of unique poses and scenes. Also, you really only need a roughly oval shaped gray blob with eyes to look like Pusheen, so the bar wasn’t that high. That being said I am happy with the outcome and think it produces interesting and (usually) realistic poses and positions.

The type of program I created is called a "Generative Adversarial Network", or GAN for short. The "Generative" term comes from the fact that it is a type of machine learning program that can generate new images similar to the ones you feed into it. This type of program is also called "Adversarial" because it is actually two different inner programs that are fighting against each other (more on this later). The "Network" in the name comes from the type of inner programs that are fighting each other, which are called "neural networks" and are a very popular type of machine learning program right now; for a casual overview of neural networks there are countless videos and other tutorials online.

In order for our pair of programs to have an idea of what we want it to do, we need to give them a lot of images similar to the ones we want it to generate (the more the better). This was a slight issue with Pusheen in particular, as there aren't that many unique Pusheen images out there (especially compared to standard machine learning datasets that have 50,000-1,200,000 images). Due to the relative lack of content, I used some tricks to make new images from the originals; a single image can be flipped, rotated, and zoomed to make many new pictures from an original one. Now for those previously mentioned two programs that fight against each other, the "generator" and the "discriminator".
The job of the "generator" is to take a list of numbers as input and make them into a new image. These random numbers can be thought of as the starting point for the image the "generator" program is about to make, like an artist that has a very basic, fluffy idea of what they are going to paint but needs to actually fill it in with shapes and colors. Some machine learning researchers refer to these lists of random numbers as the program's "imagination" or "thoughts" because the program learns to interpret them to make its own internal view of the world. Another way to think of this is when we are feeding these numbers into the generator, two lists of numbers that are have similar values will make similar cat images, whereas two lists of numbers with very different values will make very different images; the program learns that certain values of these lists correspond to certain things in the Pusheen images, so values that are close together will make images that appear similar.
The other program in the fight is called the "discriminator". This one's job is to take as input either images that the generator has created or images from the dataset we're using as examples of what to generate, and then determine where they came from. In other words, the discriminator is supposed to learn how likely it is that an image is from the generator or the real image collection. This means the discriminator will need to figure out what the images we're giving as examples look like so that it can do a good job of telling the real from the fake, where the fake images are the ones the generator makes. In the case of Pusheen, any good discriminator will not say that an image is real if it doesn't have a grey blob with a face in it.

The reason why we say these two inner programs, the generator and the discriminator, are fighting is because we set them up in a way where they are both out to make the other mess up as much as possible. By this I mean:
- the discriminator learns the flaws in the images the generator creates so that it can pick out real images from the fakes
- the generator learns how to generate images that are similar to the real ones so that the discriminator can't tell the difference

But how do we actually set up the programs so they can learn these things? Whenever we make a machine learning program, we are really having it figure out how to make its error in achieving the task we give it as small as possible. In an example of classifying cats versus dogs, this could be something as easy as the number of times it picked the wrong animal. In the Generative Adversarial Network setup, we set the goal of the discriminator to be the number of times it's wrong when judging if an image is real or fake. Then, the generator just tries to fool the discriminator by generating images that it can't tell are fake; in order to achieve this it will likely have to create images that look like the real ones, so hopefully when we see that the generator is consistently fooling the discriminator we should also see it creating realistic images! In other words, the generator sets out to do the opposite (negative) of the discriminator.
Now that each program in the pair has its objective, we start training them. A typical setup for this is
- give the discriminator some real images so it can get an idea of what a real image looks like
- give the generator some bunches of random numbers so it can generate some images
- feed the generated images from 2. into the discriminator so it knows what generated images look like
- repeat from 1.
After repeating this several hundred thousand times, we should have a generator that's great at making images like the real ones we provide, and a discriminator that's left confused by the realism of both the fake and real images (if done right it should think an image is equally likely to be real or fake). Below is a video of one of the programs training, where every 250 steps I take 16 random outputs from the generator program and display them. You can see it first learns the very basics of the images, like a grey circle-ish object on a white background, and then moves on to progressively more complicated parts like ears and tails, then faces, then attempts at objects besides cats. If you pause towards the end there are even some decent looking examples!
So now that we have a high level picture of how GANs work, we can just go get a ton of Pusheen pictures and throw them into one and get awesome new cats, right? Not so fast; in order to get my results, I had to spend several weeks tuning different knobs and switches on each of the discriminator and generator programs to get them to work just right. This involved decisions like:
- how quickly the programs learn (faster isn't always better if they learn the wrong thing!)
- the number of images I give the programs at each step
- how complicated I make the discriminator and generator
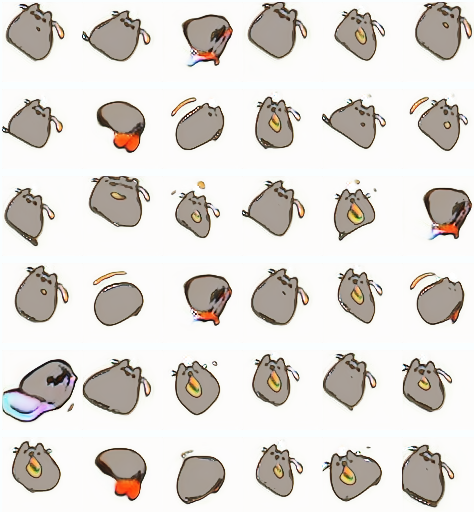
Some of these models seem to produce a few common types of pusheens in slightly different poses or situations. One possible cause for this could be because the generator has gotten too smart and knows it only has to produce certain types of images that will get past the discriminator, which is a common scenario in training GANs. The images still vary though, and I think the lack of variation is due to a lack of example images to feed the model during training. Many times when training GANs, machine learning researchers work with tens of thousands to millions of images whereas here I only had a few hundred original pictures to work with. Even though I was able to flip/rotate/zoom them to make more there are still only so many poses and situations the GAN knows about. Many times when selecting which GANs to include in this post I had to trade off between GANs which could create some novel scenes as well as some blobs, and GANs that only created one or maybe two unique images. I often chose the former, but once they were properly tuned, I think the programs were able to create some convincing images!
(I don't claim any ownership of Pusheen or anything Pusheen related, which is trademarked by Pusheen Corp.) It's no secret that my girlfriend and I both are huge fans of Pusheen the cat, which many people know from the cute Facebook sticker sets. So, for her birthday I set out to try to create a generative model to create cat pictures for her to enjoy! To set some expectations for this post, I only did this for a fun project and didn’t really know what I expected to get out of it given that in all the data available there are really only a handful of unique poses and scenes. Also, you really only need a roughly oval shaped gray blob with eyes to look like Pusheen, so the bar wasn’t that high. That being said I am happy with the outcome and think it produces interesting and (usually) realistic poses and positions. At first I thought of using a variational autoencoder to do the job, but I settled on a generative adversarial network instead because I was worried about blurriness in the images (and I had never made a GAN before and wanted to try).
The data used to train the GAN was from various Pusheen images across the Internet. After gathering a few hundred unique scenes and poses of Pusheen, I wrote some preprocessing steps to make the background white, flip, crop, and rotate them to get many more images per original image.
I assume you have some basic knowledge of how GANs work so I won't go into details here. The model I settled on was BEGAN which is a type of GAN that is easier to train, although according to some recent work most GAN improvements aren't effective given enough computing time. In summary, the ways that this model differs from vanilla GANs are:
- using an autoencoder as the discriminator, one motivation being that the discriminator can fight back againt the generator by trying to reconstruct fake images poorly compared to true images
- introducing a joint training step that has an auto-adjusting balance term which tries to maintain an equilibrium between the discriminator and generator losses
- developing an equation for a notion of convergence, which when inspected can be used as a useful debugging signal for researchers to tell if the model has converged or mode collapsed
The BEGAN model uses a loss equation based on the Wasserstein distance, except its goal is to minimize the absolute value of the autoencoder losses on the real and fake images instead of the images themselves. In practice it drops the absolute value and minimizes the reconstruction loss on real images minus the reconstruction loss on fake images. Additionally, it introduces a weighting term on the fake reconstruction loss which changes proportaional to the difference between the fake and real reconstruction losses; this serves to maintain a balance between the discriminator and generator so one does not easily win over the other.
I'll be releasing the code soon but to summarize, the architectures and hyperparameters that typically worked well with for the discriminator and generator were:
- leaky relu for the activation function, with alpha=0.2
- batch normalization
- stride 1 convolutions followed by 2x nearest neighbor resizing in G
- stride 1 convolutions followed by 2x2 average pooling in D
- four sets of convolutional layers in each D and G, where each is repeated 2-4 times with vanishing residual connections between
- 32 or 64 filters per convolutional layer in D
- 32 or 64 filters per convolutional layer to start in G, then doubling for each successive set of layers (so if they were repeated 3 times and I started with 32, the layer depths would be [32, 32, 32, 64, 64, 64, 128, 128, 128, 256, 256, 256])
- a latent dimension of 100
- a learning rate of either 1e-4, 5e-4, or 1e-3
I did a fair amount of hyperparameter searching to get a model that worked (keep scrolling for some failures) but I think it ended up being a pretty decent cat generator. Below is a training video of one of the models that I use in the demos, where every 250 steps I take 16 samples from the generator. You can see it first learns the very basics of the images, like a grey circle-ish object on a white background, and then moves on to progressively more complicated parts like ears and tails, then faces, then attempts at objects besides cats. If you pause towards the end there are even some decent looking samples!
For some models there were definitely signs of mode collapse, and even some of the ones I picked as demos can lack novelty. I think this is in part attributed to the fact that while I was able to artificially expand the dataset with preprocessing tricks, there were only a few hundred original images to work with so the amount of variety the GAN could learn was limited from the start. I also found a trade-off between mode collapse and models that could produce both a healthy variety of images and some not fully formed Pusheens, and often times used the latter for the generators in this post. I know it isn't the most diverse generator, but even still I'm overall happy with the results.
Results
Now for the part everyone is here for! While all the images thus far were created by my program, here are some more selected samples and demos from the finished models; note that especially if you're on mobile it may take ten or more seconds to load, but I'm working on it! Use the dropdown to select between a few different models. As a warning, some of them can be somewhat creepy, because while the program aims to make pictures that look like the Pusheen images it has seen, it doesn't always do well. However, if you keep the input values small it usually makes some cat looking pictures. Don't worry though, they're just pictures!
Remember that each image corresponds to a different starting point; here I gave the program four different starting points, one in each corner, and then gradually blended one starting point into the other corners', showing the resulting cats:
Here I interpolated between four different latent vectors, one in each corner, and show the resulting cats:

Now I suggest trying it out for yourself! Recall that a GAN is a pair of programs that are setup to trick each other, where the generator is the one that takes in random numbers to make images. This means that each time you click the buttons below to make the images change, the code I wrote to run the generator program in the browser grabs some random numbers as inputs and then displays its outputs as images in your browser. Click the button below to get a bunch of random ones.
Now I suggest trying it out for yourself! I rewrote the generator program using tensorflow.js, a Javascript Tensorflow library so that everything could run in the browser. Click the button below to get a bunch of random ones.

The corners demo isn’t very usable on smaller screens, so try using a laptop or dekstop!
Another awesome property of GANs is that one can do arithmetic with the numbers we feed into it, and the same arithmetic is seen in the images generated. A common example of this is with faces, as seen below (image from here):

Here they take the input numbers for men with glasses, subtract from them the input numbers or a man without glasses, and then add to them the input numbers for a woman without glasses, and when they take the resulting numbers and generate images they get women with glasses! This is a super cool result of GANs that visibly shows us that the input numbers they take in have some meaning to us too. If you were asked to draw a picture of the result of "man with glasses" - "man" + "woman", you would likely draw a woman with glasses; this is what we ask the GAN to do here too, because these input numbers are the program's version of our thoughts when we internally visualize what the men and women with and without glasses look like. While this demo is admittedly not as clear for Pusheen as I'd wished, it's still interesting to play with.

I included an example above, where there's a "cat with a taco" that we subtract a "left leaning cat" from and add in a "right leaning cat with leash" (I understand I'm being generous with what these extra objects are) and the result is a "right leaning cat with a leash and a small taco". You can also try for yourself below, changing the triplets of input numbers that are used to make the start/subtracted/added images and see what the result is on the right!
Another awesome property of GANs is that one can do arithmetic in latent space and the resulting latent vectors generate semantically reasonable images:
-
+
=
Of course getting the model to this state didn't happen right out of the box, so here are some happy accidents that happened along the way:


Water-sheens


Fire-sheens

Earth-sheens

Air-sheens


Conjoined pusheens

Some tail balls

Yellow?


I hope you liked my cat generator as much as my girlfriend did! If you want to see more cool things like this (or send me any cute or silly cats you generate) then follow me on twitter, I've got some more fun demo ideas in the works!
I'd also like to give a huge thank you to the following people who reviewed this post and gave feedback on it: Kailyn Doiron, Chris Grimm, Kevin Paeth, Jasper Snoek. Loading spinner from here.